
If you’ve spent any time in the storage industry, you’ve probably had the same déjà vu I have. A customer walks in with a problem—they’re running out of capacity, they need to move data between sites, they want to protect against disaster without breaking the bank—and you think: I’ve heard this one before.
Because you have. We all have. For decades.
The truth about storage and data management is that the fundamental problems haven’t really changed. What’s changed is everything around them—the scale, the geography, the economics, the expectations. And that gap between old problems and new realities is exactly where the opportunity lies.
The Problems That Never Go Away
Talk to any storage administrator today, and you’ll hear the same concerns that have echoed through data centers for the last 30 years: backup and disaster recovery (DR), storage tiering, archive, migration. The workflows are remarkably consistent. The question has always been some variation of: How do I protect my data, keep what I need accessible, and not go broke doing it?
Reducing the amount of data sitting in expensive hot storage has been a priority since hot storage existed. Deduplication and compression have been part of the toolkit for years—first through custom, proprietary methods baked into hardware, then through inline or at-rest approaches that traded off between performance and efficiency. Every generation of storage technology has tried to help customers make the most of the capacity they have.
And every generation of storage technology has faced the same awkward reality: data grows. It always grows. Historically, adding capacity wasn’t always straightforward. You’d hit a wall, buy another shelf, maybe rearchitect your pools—it was disruptive, expensive, and rarely as seamless as the brochure promised.
Then there’s the eternal balancing act of performance, capacity, and cost. All-flash arrays deliver screaming performance but at a premium. Hard disk gives you depth and density but not speed. Hybrid approaches try to split the difference. Every storage buyer has sat in front of a spreadsheet trying to thread that needle.
And underneath all of it sits a deceptively simple question that has never had a simple answer: Where should the data actually live? On a user’s workstation or laptop? On-prem shared storage? Or, more recently, in the cloud? The answer has always depended on the workflow, the budget, and the team—and it’s only gotten more complicated.
Same Problems, Different World
None of these challenges are new. But three forces have fundamentally changed the context in which they need to be solved.
Cloud reshaped expectations around flexibility and access. The rise of S3, Azure Blob, Google Cloud Storage, DropBox, and other cloud datastores didn’t eliminate on-prem storage, but it did create a world where multi-site data sharing went from a nice-to-have to table stakes. Customers now expect their data to be reachable from anywhere, composable across locations, and not locked into a single deployment model.
AI is driving an explosion in data creation and data consumption simultaneously. Models need to be trained, inference needs to be served, and the datasets feeding both are massive and growing. Storage infrastructure that was designed for predictable, human-driven workflows is being asked to support something very different.
A post-COVID distributed workforce scattered teams across geographies and turned “the office” into a concept rather than a place. Collaboration workflows that once assumed everyone was on the same LAN now span continents. The infrastructure has to keep up.
These forces didn’t invent new problems; they raised the stakes on the old ones. Backup and DR still matter, but now across hybrid environments. Tiering still matters, but now across on-prem and cloud. Total cost of ownership (TCO) still matters, but now the calculus includes cloud spend, egress fees, and the operational cost of managing sprawl.
And perhaps most importantly, the people managing these systems (the storage admins, the IT teams) need solutions that make their jobs easier, not harder. TCO isn’t just about the sticker price of hardware and software. It’s about the human cost of complexity. If your data management solutions add to the burden instead of reducing it, you’ve already lost.
A Fresh Look at Familiar Ground
This is where I think OpenDrives is uniquely positioned.
Atlas was built on ZFS, which handles both deduplication and compression natively, achieving a combination of high efficiency, high resiliency, and high performance entirely in software, without expensive RAID HBAs. That’s not a minor architectural detail. It means customers get enterprise-grade data reduction without the proprietary hardware tax.
When data grows, and it will, Atlas can expand dynamically. Scale up within a system, scale out across systems, or extend into the cloud. No forklift upgrades. No painful re-architecture.
The performance-versus-cost balancing act? Atlas supports all-flash, all-disk, or hybrid configurations, with intelligent caching that leverages the capacity of deep, affordable hard drives alongside the speed of flash and memory caching for the fastest access tier. Customers don’t have to choose between performance and budget—they can architect for both.
And on the question of where data should live, Atlas runs on-prem or in the cloud. Whether you’re extracting maximum performance from the hardware in your data center or optimizing cloud resources in AWS or Google Cloud, Atlas adapts. It supports many simultaneous users with the performance, reliability, and resiliency that shared workflows demand.
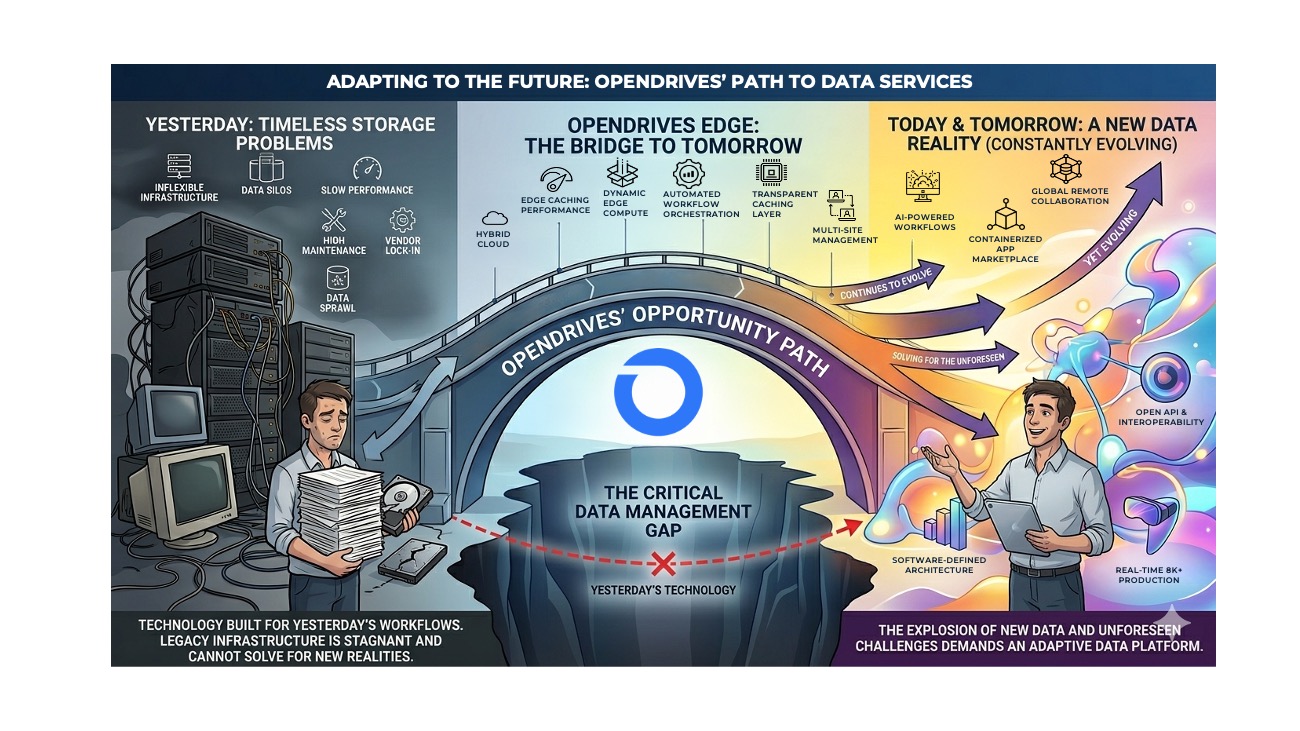
But we know Atlas alone isn’t the whole answer. Not anymore. The world has gotten bigger and more distributed, and our customers need their storage platform to reach further.
That’s why we built OpenDrives Edge.
Edge connects Atlas to the cloud, to third-party NAS, and to other Atlas systems in a way that wasn’t possible before. It’s the bridge between the on-prem performance our customers rely on and the distributed, multi-site, cloud-connected reality they operate in today. It takes the workflows our customers have always had—backup, tiering, archive, migration, multi-site collaboration—and extends them across the boundaries that used to define the limits of what a storage platform could do.
What Comes Next
We’re taking a fresh look at the problems our customers face and the solutions we can provide. OpenDrives Edge is the beginning, a new set of software solutions designed to work hand-in-hand with the Atlas systems our customers have come to rely on.
I’m looking forward to unveiling these new solutions at NAB in Las Vegas and, more importantly, to hearing directly from our customers about what else we can do to solve their problems. The goal has always been the same: help our customers focus on what they care about, their creative work, their business outcomes, their content, and spend less time worrying about IT infrastructure and data management.
The more things change, the more they stay the same: it’s true in life and it’s often true with your data problems. But the solutions? Those should always be evolving.
To learn more about OpenDrives Edge and catch up on all the latest OpenDrives product buzz, check out our press room.


